
Designing quantum circuits may seem a challenging task, but the longer one does it, the easier it gets with another approach. However, there is one thing that remains a problem regardless of how experienced you are with quantum computing – moving a state from one qubit to another.
In classical computing, you can simply read the result of your computations mid-air, copy it to another set of bits, and carry on like nothing happened. It is, physically, impossible to do in quantum computing, though. A theorem, known as the No-Cloning Theorem, explains why.
The No-Cloning Theorem is a fundamental principle in quantum mechanics, which states that it is impossible to create an identical copy of an arbitrary unknown quantum state. In simpler terms, you cannot duplicate an unmeasured qubit like you would with classical bits. I will save you the precise math that underpins it. What is important to remember, though, is that it is related to the destructive nature of the READ operation in QPUs. One cannot copy without reading what is to be copied in the first place. And reading a QPU result inevitably destroys any quantum state that was there, leaving only the classical result in the process.
Fortunately, a protocol exists that allows us to “move” an arbitrary quantum state from one qubit to another without destroying it. It is called quantum teleportation.
What the Teleportation Actually Means
No, unfortunately we will not feel like Spock from Star Trek. Nor will our qubits. Quantum teleportation is actually quite a misleading term. It does not instantly move matter from one place to another. It does not even do it with any information we may wish to transfer. It is much more grounded.
Quantum teleportation is a protocol that allows a sender (let her be Alice) to transmit a qubit to a receiver (let him be Bob) using a shared entangled quantum state and two bits of classical communication.
The protocol assumes Alice and Bob share an e-bit in the state |𝜙+⟩. The e-bit (entangled bit) in quantum computing refers to a quantum state that is shared between two parties and exhibits correlations that cannot be explained by classical physics. The state of an e-bit is represented in one of the Bell states. This shared state is essential for various quantum information processing tasks, including, unsurprisingly, quantum teleportation.
The e-bit could have been prepared in the past or through a third party or complex distributed process. Either way, how they both obtain the Bell state is of no concern to the protocol.
In addition to her part of the e-bit, Alice possesses a qubit Q that she wishes to transmit to Bob. Its state is unknown to both parties, and it may be entangled with other systems they cannot access. It is also important that the quantum teleportation protocol is only worth considering if physically sending the qubit Q to Bob is considered infeasible, for example because the quantum system would decohere before it reaches its destination. Alice can send classical information to Bob, though.
Remember that it is not possible to transmit quantum information using classical communication alone due to the no-cloning theorem. However, with the shared e-bit in place, Alice and Bob can accomplish their task through the quantum teleportation protocol.
As you can see, quantum teleportation, despite a fancy name, is just a protocol allowing for sending quantum information using entanglement and classical communication over arbitrary distances. Let us take a look at it.
The Protocol
The protocol involves a couple of steps which I will walk you through in order to get a good grasp of the topic. And nothing helps learning like a good visualisation of the subject.

The protocol consists of the following steps.
- Alice performs a controlled-NOT operation on the pair (A, Q), with Q being the control and A being the target, and then performs a Hadamard operation on Q.
- Alice then measures both A and Q, with respect to a standard basis measurement in both cases, and transmits the classical outcomes to Bob. Let us refer to the outcome of the measurement of A as a and the outcome of the measurement of Q as b.
- Bob receives a and b from Alice, and depending on the values of these bits he performs these operations:
- If a=1, then Bob performs a bit flip (or X gate) on his qubit B.
- If b=1, then Bob performs a phase flip (or Z gate) on his qubit B.
- That is, conditioned on ab being 00, 01, 10, or 11, Bob performs one of the operations I, Z, X, or ZX on the qubit B.
As a result, the state of qubit B is identical to the state of qubit Q the first step was applied.
It is important to note that once Alice measures her qubits, the outcome of Bob’s measurement is instantly affected. In other words, the probability of getting one of the eight possible outcomes is set. However, it is not enough for Bob to get the desired state. He still needs to conditionally apply one or more operations in order to complete the state’s transfer. Perhaps the instantaneousness of the measurement probability setting inspired the name, but nothing in reality is teleported in this protocol, or happens at the same moment.
Under the Hood
I hope that you already have a good understanding of what quantum teleportation actually is. However, a step-by-step guide is not really step-by-step if it does not contain a detailed walkthrough of what is happening under the hood.
Setup
The first step is to create a Bell state from Alice’s and Bob’s qubits. Let us choose the |𝜙+⟩ state, which is 12(|00⟩ + |11⟩) when expanded. Then, I recommend that we actually initialise the Q qubit to some arbitrary values, since it makes the algebra easier to follow, and does not obscure any important details. We can pick |1⟩ for example.
With such choices we have now a three-qubit quantum system that can be represented by the following equation.
![{"id":"43-0","code":"\\begin{align*}\n{|\\phi^{+}⟩\\otimes|1⟩}&={\\left(\\frac{1}{{\\sqrt[]{2}}}|00⟩+\\frac{1}{{\\sqrt[]{2}}}|11⟩\\right)\\otimes|1⟩}\\\\\n{\\,}&={\\frac{1}{{\\sqrt[]{2}}}|001⟩+\\frac{1}{{\\sqrt[]{2}}}|111⟩}\\\\\n{\\,}&={\\frac{|001⟩+|111⟩}{{\\sqrt[]{2}}}}\t\n\\end{align*}","backgroundColorModified":false,"aid":null,"backgroundColor":"#ffffff","font":{"family":"Arial","color":"#000000","size":11},"type":"align*","ts":1742283950753,"cs":"KZlAQMY4s/Fddql+4pAqiA==","size":{"width":298,"height":136}}](https://lh7-rt.googleusercontent.com/docsz/AD_4nXfyUk0-rF-3Ldmp6Fh5qGpTJUZhY8EiUeJEed5pndrO7qEmBfLcSmaw_x7kwxqebI1C7mhDx6CgMypHyD9_roiwN27plEqaHTNv78Q_xNxpezgUIiKUF5CXkzXeil21kUzbNhjUwA?key=8QcjTf1a1qbkmPBhIp1n5Jpb)
The three-qubit kets may look intimidating at first, but it’s quite easy to reason about them. They’re ordered left to right, and are essentially a concatenated |𝜙+⟩ Bell state and the state qubit (|1⟩). So we have Alice’s qubit, Bob’s qubit, and the state qubit represented in two, equally probable kets.
If you are not a big fan of linear algebra, you can alternatively use the circle notation (I described it in detail here). It is how the same quantum system can be represented using this alternative notation.

Alice’s Steps
Next, it is time for Alice to make her move. She applies a CNOT (CX) gate for her qubit (A), using the state qubit (Q) as the control qubit.

It may be a bit counterintuitive, but if you apply more than one quantum gate to qubit(s), you have to multiply their respective matrices first, before calculating the tensor product of the entire system. This is how the result of Alice’s actions looks linearly.
![{"type":"align*","font":{"family":"Arial","color":"#000000","size":11},"code":"\\begin{align*}\n{CNOT\\left(q_{a}\\right)H\\left(q_{s}\\right)\\otimes\\frac{|001⟩+|111⟩}{{\\sqrt[]{2}}}}&={\\frac{|010⟩+|100⟩-|011⟩-|101⟩}{2}}\t\n\\end{align*}","backgroundColorModified":false,"backgroundColor":"#ffffff","id":"43-1-0-0","aid":null,"ts":1742466188709,"cs":"l2WLSiYoxr1Hs+j34vlkZg==","size":{"width":496,"height":42}}](https://lh7-rt.googleusercontent.com/docsz/AD_4nXcV0VTog0gzHFjGtT8LI2t415HwUECjY_5-TQLmA7NCdusNukBs2awwN7G4dIdSkS0WM8ekfUOQOnf87xirxyyEOqTyrVUPVt3GEydq3Rp1-ksYmQo8oq5-7UIkUS2zh3K_EXnv?key=8QcjTf1a1qbkmPBhIp1n5Jpb)
The CNOT gate is primarily used to entangle the state qubit with Alice’s qubit. However, in our example it will also flip the value of Alice’s qubit since the state qubit’s value is |1⟩. The Hadamard gate will not only set the state qubit into superposition, but it’ll also affect its phase (which is reflected with minuses in the equation).
In the circle notation, our quantum system now looks like this.

The register may seem complicated now, and indeed it is if we treat all the qubits together. However, we can also think of them separately. Alice’s qubit is still in superposition due to the Bell state applied in the preparation step. The CNOT gate flipped the bits, but she can still read (if measures) 0 and 1 with equal probability. We have four possible readable states, and each two contain either 0 or 1 as the first qubit.
The same situation is with Bob’s qubit – he can still read 0 or 1 with equal probability when measured. The only difference is with the state qubit. Since we applied a Hadamard gate to it, we put it effectively in superposition of 0 and 1. Also, I have already mentioned that its phase was flipped.
Alice then measures her two qubits (the state qubit and Alice’s qubit), collapsing their joint state and producing classical bits that are stored in her classical register. This measurement step transfers the quantum information from the state qubit to Alice’s classical bits. They are sent then to Bob, so he can proceed with his part of the protocol.
Please remember that our quantum system is entangled, so Alice’s measurement affects Bob’s one. Depending on what she reads, possibilities for Bob’s readout are immediately set. However, as I already discussed, this evenement alone is not necessary to transfer the state qubit’s state to Bob’s qubit.
Bob’s Steps
Bob’s actions depend on outcomes of Alice’s computation, or more precisely, what bits were sent via the classical channel. The protocol branches now into four possible paths, implemented with two, conditionally applied gates. Which of these two gates is applied depends on two bits sent to Bob by Alice.

1. Bob receives 00.
This is the easiest path to implement. The only thing Bob has to do, is to apply an identity operation (I) to his qubit (or do nothing, since the identity operation does not change the state of a qubit).
However, how come that Bob’s qubit already is in the desired state. Let us look at the state of the register from the previous step. Before Alice’s measurement we had four possible readable outcomes: |010⟩, |100⟩, |011⟩ and |101⟩. Just as a reminder, the state qubit is the right-hand most, and Alice’s qubit is the left-hand most.

If both yielded 0, then it means that our register is in the |010⟩ state (indicated by the full circle), and Bob’s qubit already has the value of |1⟩. Indeed, nothing has to be done.
2. Bob receives 10
It means that Alice’s qubit yielded 1, and the state qubit yielded 0. This indicates that the register is in the |100⟩ state. In this situation Bob applies a CNOT gate to his qubit. In linear algebra it transforms the whole system like in the following equation.

This is how the register looks after Alice’s measurement and the CNOT gate application.

Again, Bob’s qubit is now in the original state qubit’s state (|1⟩).
3. Bob receives 01
If Bob receives 0 from Alice’s qubit and 1 from the state qubit, then he applies only a CZ gate. Why so? If you look at the register, then you can see that Bob’s qubit seems to be already in the right state (it is the -|011⟩ part of the state equation). However, you may have noticed that there is a minus sign in front of this part of the state. This means that the phase was flipped during the teleportation, and must be reverted. It is done with the CZ gate like in the following equation.

And here is the final result for the registry written in the circle notation.

The phase is now rotated back, and Bob again reads 1 from his qubit.
4. Bob receives 11
In the final possible branch, Bob receives 1s from both qubits read out by Alice. In this case, he must flip both the value of his qubit, and the phase. It transforms the register in the following way.

And the final state looks like this.

Again, Bob’s qubit ends up in the same state as the state qubit originally was.
Conclusion
Quantum teleportation is a process that allows for the transfer of quantum information from one location to another without physically moving the quantum state itself. This process involves three parties: Alice, who holds the quantum state to be teleported; Bob, who will receive the state; and a classical communication channel between them.
The process begins with Alice and Bob sharing an entangled pair of qubits. Alice then performs a Bell state measurement on her qubit (the one she wants to teleport) and her half of the entangled pair. This measurement results in two classical bits being sent to Bob through the classical communication channel.
Bob, upon receiving these two bits, knows exactly which operation to perform on his half of the entangled pair to recover the original quantum state. This operation can be a bit flip, a phase flip, or both.
The four possible outcomes of Alice’s measurement and Bob’s subsequent operations are:
- If Alice sends 00, Bob does nothing (identity operation, I) because his qubit is already in the desired state.
- If Alice sends 10, Bob applies a CNOT gate to his qubit. This operation flips the value of his qubit, making it identical to the original state.
- If Alice sends 01, Bob applies a CZ gate to his qubit. This operation corrects the phase flip that occurred during teleportation.
- If Alice sends 11, Bob applies both a CNOT and a Z gate to his qubit. This operation flips both the value and the phase of his qubit, making it identical to the original state.
In all cases, after receiving the classical information from Alice and performing the appropriate operations, Bob’s qubit ends up in the same state as the original quantum state that Alice wanted to send. In other words, the quantum teleportation protocol allows sending arbitrary quantum states over arbitrary distances in a way that works around the No-Cloning Theorem.

![{"type":"$$","code":"$$\\begin{bmatrix}\n{\\frac{1}{{\\sqrt[]{2}}}}&{\\frac{1}{{\\sqrt[]{2}}}}\\\\\n{\\frac{1}{{\\sqrt[]{2}}}}&{-\\frac{1}{{\\sqrt[]{2}}}}\\\\\n\\end{bmatrix}\\begin{bmatrix}\n{1}\\\\\n{0}\\\\\n\\end{bmatrix}$$","backgroundColor":"#ffffff","font":{"color":"#000000","family":"Arial","size":11},"backgroundColorModified":false,"id":"2-0","aid":null,"ts":1739954474319,"cs":"jxu4BASLggoUWhK1ORQX4Q==","size":{"width":120,"height":56}}](https://lh7-rt.googleusercontent.com/docsz/AD_4nXebjvzkGoId7l25Y8OdW0-w0QxPZL8EC5MOJtlCwBNUeef7BcZLqcYwYQtIzLucLmMv1IrCcOHIk3l2-hqsm5BkKRPed9_xTVRdgUaSeR1PeQG684TTcab0atEMJMvxCsy3oN365g?key=Iyls7HWGtK5e7qc-A4Cb9byi)


![{"backgroundColorModified":false,"code":"$$\\begin{bmatrix}\n{\\frac{1}{{\\sqrt[]{2}}}}&{\\frac{1}{{\\sqrt[]{2}}}}\\\\\n{\\frac{1}{{\\sqrt[]{2}}}}&{-\\frac{1}{{\\sqrt[]{2}}}}\\\\\n\\end{bmatrix}\\begin{bmatrix}\n{1}\\\\\n{0}\\\\\n\\end{bmatrix}=\\frac{|0⟩ + |1⟩}{{\\sqrt[]{2}}}$$","id":"2-1","aid":null,"type":"$$","font":{"color":"#000000","family":"Arial","size":11},"backgroundColor":"#ffffff","ts":1739962299511,"cs":"fvcxqunYOS3tt1AKRbLAsg==","size":{"width":214,"height":56}}](https://lh7-rt.googleusercontent.com/docsz/AD_4nXdQdf3x8btIPwEsu7Kl2HMPAHrnBaTlEVpp0MDiIcZ5sDJRdPJl831BjcDKAO8ot3oaTzEHREt1Aqo0ndVTyhwSRS_woyRNXiuZA4YWEkXxXumIGtSS8v3JHG9bIjRC8ybVJwf3?key=Iyls7HWGtK5e7qc-A4Cb9byi)










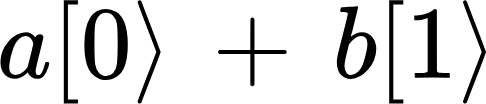
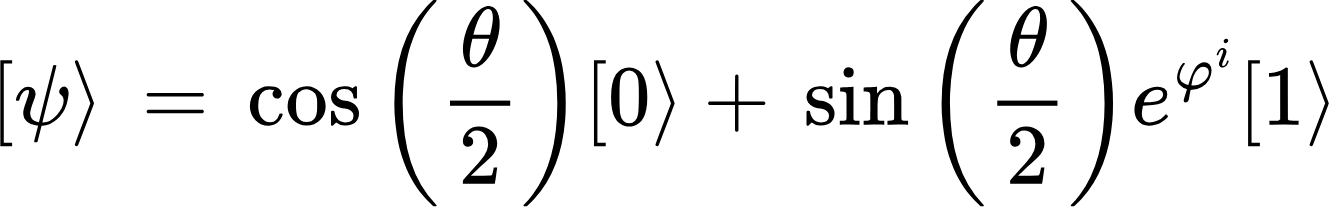
{kind=link}